Avoiding Pitfalls During Service Deployments
DevOps Kubernetes DeploymentsNowadays deploying software on the cloud using technologies like Docker and a container orchestration system (k8s, ECS, docker swarm, etc.), has become effortless, leveraging strategies like “rolling updates” and “canary releases” which are practically included and require no additional undertaking. While this ensures that we can release our software with zero-downtime to our customers, what happens when we introduce a change in the system that we cannot go back from?
Challenges deploying distributed systems
The most common reason for making “hard to roll forward” changes in a system is a change of protocol or changes in the way a service handles data reads or writes. When deploying a new version of a service, it may work perfectly well from the previous version to the next, but oftentimes a disruption may occur, during the time of transition between the two states of the service.
For example, in a staging environment, you might run only one instance of your application, and deploying it is a one-step process, but what will happen in a live environment where you possibly run hundreds of containers of the same service? Even though you have written tests for the new changes and everything passes with a green light in your CI system, that environment commonly differs from running the application at full scale. No one usually performs tests running the old and new version of the service at the same time, which can happen during a rolling update if you run multiple replicas of the same service.
Also, nowadays the microservices architecture is increasingly popular, so now you have many different services that need to communicate with each other, and more importantly, depending on one another or depending on a shared state.
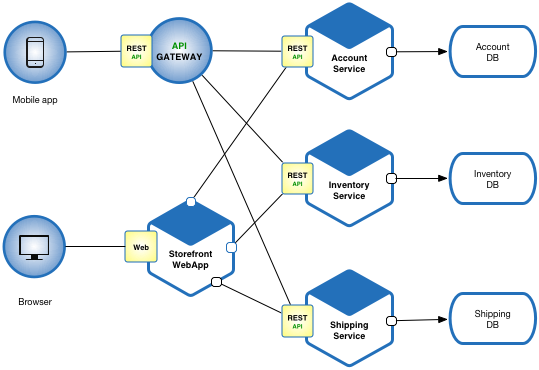
Deployment of such an architecture can present additional challenges. Services may run different versions of the software, and as a result, they could read or write the state differently, which can cause outages in the system or induce some unexpected behavior.
Furthermore, monorepos have become an increasingly popular software development strategy, where code for many (or all) projects, resides in the same repository which in turn has made code refactoring much easier due to the code being in one big repository and has enabled engineers to make cross-cutting changes in multiple services in a single commit. This can lead to a misconception of believing that these changes are atomic, similar to making changes in a monolithic application.
Making changes in multiple services at once does not mean you get to deploy those services in the same time as one single unit, and can break the behavior of your system during the transition from one version to the other.
Two-step deployment strategy
The most common pitfall when making changes to a system, is the modification in behavior or protocol of a service (as we’ve shown above). We can demonstrate this further with a simple example.
Let’s create a scenario, involving a service - we’ll call it Metadata, which can store and provide data in a key value format to other services. Let’s say we designed the Metadata service to provide the data as a JSON object with key/value pairs. Example:
{
"metadata": {
"phone": "123456",
"country": "US",
"foo": "bar"
}
}
Because of a business requirement, we decided that we’ll need additional information for each associated key such as: is the key read-only or not, what type it is, when was it modified, etc. So we decided to provide this data as an array of objects, where each object represents one key/value pair, along with the other information, like so:
{
"metadata": [
{
"key": "phone",
"val": "123456",
"read_only": false,
"created_at": 1578749018,
"updated_at_": 1578749018
...
},
...
]
}
How should we continue about this? We cannot simply change the behavior of the Metadata service to provide the data as an array, since our other services won’t be able to read the newly provided data. We’ll need to ensure that we can transition this change smoothly, without introducing any breaking changes.
We can use a strategy that involves deploying our services in two steps. In the first step we’ll need to update our service to present both formats of data, the old metadata property, alongside with the new metadata_v2 property:
{
"metadata": {
"phone": "123456",
"country": "US",
"foo": "bar"
},
"metadata_v2": [
{
"key": "phone",
"val": "123456",
"read_only": false,
"created_at": 1578749018,
"updated_at_": 1578749018
...
},
...
]
}
After we deploy the new version of Metadata, the second step involves updating all of the other services that depend on reading the new version of the data. This way we can be sure that we won’t break the functionality of our system.
Backwards compatibility
There is one caveat to this strategy - in order to be sure that Metadata is backward compatible, the services that depend on it need to fallback to the old metadata property, in case the new property is missing. It is good practice to let the changes sit for a while before the last step - dropping support for the old property.
At every revision of the code for each application, make sure to test and verify that the change is safe for rolling forward or backward, before continuing with the deployment. After we have performed thorough tests of rolling forward, then rolling back both the Metadata and the other services, we can safely continue to drop support of the old property. First we’ll perform the updates in the code to only read from the new property metadata_v2, and then we’ll remove the code in Metadata that provides the old metadata property.
This type of “two-step” deployment strategy can be applied to similar scenarios that involve some kind of change in behavior in our services, whether if it’s refactoring tables in a database, renaming columns and properties, data migrations, to API changes which involve multiple services.
A set of practices
- Ensure that services between versions can coexist.
- Test rolling forward with continuous traffic if you can, since most of the issues happen during a transition.
- Maintain order of the deployments across multiple services - consumers go before providers during an upgrade and do backward steps during a downgrade.
Conclusion
Making changes that are not safe for rolling back from can easily be overlooked, but as long as we plan the phases that need to be taken and mind the order of the deployment of the services, also verify that the services can be safely rolled back and test upgrade and downgrade scenarios, we can make sure our system is reliable and eliminate any disruptions.